Authors: M. A. Kraus & M. Drass
Source: Glass Structures & Engineering | https://doi.org/10.1007/s40940-020-00132-8
Abstract
’Big data’ and the use of ’Artificial Intelligence’ (AI) is currently advancing due to the increasing and even cheaper data collection and processing capabilities. Social and economical change is predicted by numerous company leaders, politicians and researchers. Machine and Deep Learning (ML/DL) are sub-types of AI, which are gaining high interest within the community of data scientists and engineers worldwide. Obviously, this global trend does not stop at structural glass engineering, so that, the first part of the present paper is concerned with introducing the basic theoretical frame of AI and its sub-classes of ML and DL while the specific needs and requirements for the application in a structural engineering context are highlighted.
Then this paper explores potential applications of AI for different subjects within the design, verification and monitoring of façades and glass structures. Finally, the current status of research as well as successfully conducted industry projects by the authors are presented. The discussion of specific problems ranges from supervised ML in case of the material parameter identification of polymeric interlayers used in laminated glass or the prediction of cut-edge strength based on the process parameters of a glass cutting machine and prediction of fracture patterns of tempered glass to the application of computer vision DL methods to image classification of the Pummel test and the use of semantic segmentation for the detection of cracks at the cut edge of glass. In the summary and conclusion section, the main findings for the applicability and impact of AI for the presented structural glass research and industry problems are compiled.
It can be seen that in many cases AI, data, software and computing resources are already available today to successfully implement AI projects in the glass industry, which is demonstrated by the many current examples mentioned. Future research directories however will need to concentrate on how to introduce further glass-specific theoretical and human expert knowledge in the AI training process on the one hand and on the other hand more pronunciation has to be laid on the thorough digitization of workflows associated with the structural glass problem at hand in order to foster the further use of AI within this domain in both research and industry.
Introduction
Artificial Intelligence, or AI for short, is probably the term that leads to the most animated discussions today in companies of the tech sector, universities and start-ups, but also in other low-tech companies with a small degree of digitization. Due to a progressing digitization of all sectors of industry (Barbosa et al. 2017; Lampropoulos et al. 2019; Schober 2020) while costs of data processing and storage steadily decrease (Kurt Peker et al. 2020; Kraus and Drass 2020a), AI is currently paving its way from the subject of academic considerations into both private and professional everyday life in a wide variety of forms.
Most people in academia and industry who are not familiar with the field of AI imagine the technology to be similar to popular science fiction movies like “Terminator”, “Blade Runner”, “Matrix” or “A.I. Artificial Intelligence”. Today however AI is present in everyday’s life in less spectacular and humanoid forms such as spam filters, recommender systems or digital language assistants such as “Alexa” (Amazon) or “Siri” (Apple) (Kepuska and Bohouta 2018). An impression of the effects of AI on engineering contexts can be gained by looking at the developments and findings concerning the self-propelled car (Badue et al. 2019).
There a great number of questions have to be addressed on several levels, ranging from ethical and legal concerns w.r.t. reliability of AI and consequences of failure (Holstein et al. 2018; Greenblatt 2016) to very technical concerns such as the formulation of learning problems or the processing of a growing amount of collected data (Hars 2015; Daily et al. 2017). A lot of similar questions arise in case of applying AI in a civil engineering contexts with different pronunciation. However, this paper will show that AI offers many new potentials and certain advantages over existing methods for the use in civil and especially glass engineering, development and practice.
Basically, the disciplines of statistics, numerics and optimization play a major role in understanding the data, describing the properties of a data set, finding relationships and patterns in these data and selecting and applying the appropriate AI model. Although nowadays AI software libraries such as Tensorflow (Abadi et al. 2016), Keras (Chollet et al. 2015) or PyTorch (Paszke et al. 2019) provide many necessary functionalities for no monetary cost, the authors consider it essential for a successful application of AI in the engineering sciences and especially in structural glass engineering that only a reasonable combination of the methodological knowledge of AI and the expert knowledge of the engineer result in meaningful and valuable tools.
Hence, the intention of this article is threefold: it serves as a short introduction on the background and definitions of AI technology, based not on a data science background, but on the background of engineers as AI users; illustrative examples from a wide range of glass engineering topics elaborate capabilities and impact of AI methods on the field; highlighting future potentials of AI for glass engineering gives an outlook on trends and gains. Therefore this paper is structured as follows: First, the basic concepts and nomenclature of AI, Machine Learning (ML) and Deep Learning (DL) are introduced and explained.
Based on the theoretical background, the second part of the paper reviews successful applications of AI in glass and façades related fields of science and engineering. In the third part, current and potentially promising future trends for the implementation and application of AI in the glass and façade sector are presented. The last section presents a summary and conclusions from the findings, together with an outlook on the future of AI in construction and related industries.
Basics on AI, machine learning and deep learning
This section provides a non-comprehensive introduction on the topics of artificial intelligence, machine learning and deep learning, whereas a theoretically more substantial and elaborated description of AI and its sub-classes can be found in (LeCun et al. 2015; Binkhonain and Zhao 2019; Dhall et al. 2020; Goodfellow et al. 2016; Frochte 2019; Wolfgang 2017; Rebala et al. 2019; Chowdhary 2020). Furthermore, (Goulet 2020) gives in particular a textbook-like introduction to AI topics with a focus on civil engineering.
Artificial intelligence, algorithms, models and data
Looking at Fig. 1, one can see that AI is the umbrella term for all developments of computer science, which is mainly concerned with the automation of intelligent and emergent behavior (Chowdhary 2020).

Thus, AI is a cross-disciplinary field of research for a number of subsequent developments, algorithms, forms and measures in which artificially intelligent action occurs, which was presented initially at a conference at Dartmouth University in 1956 (Brownlee 2011; McCarthy et al. 1956; Moor 2006). AI is dedicated to the theory and development of computational systems, which are capable of performing tasks which require human intelligence, such as visual perception, speech recognition, language translation and decision making (Brownlee 2011). Hence, a number of AI sub-fields have emerged, such as Machine Learning (Turing 1950), which historically has focused on pattern recognition (Marr 2016). Parallel, the first concept of a neural network was developed by Marvin Minsky (Russell and Norvig 2020), which paved the way for deep learning.
Interestingly, artificial intelligence so far has had to overcome several lean periods (“AI winters”) over the years (Crevier 1993), but at this very present time seems promising for a broad breakthrough of the AI technology in several branches as digital, computational and monetary resources are in place to provide fertile conditions (Goodfellow et al. 2016; Schober 2020; Kraus and Drass 2020a).
From a computer science aspect, it is distinguished between weak (or narrow) and strong (or general/super) AI (Russell and Norvig 2020; Goodfellow et al. 2016; Frochte 2019). In particular weak AI deals with concrete application problems and their solution, for which kind of “intelligence” is required from the basic understanding. Commonly known digital assistants such as Siri from Apple (www.apple.com/sir) and Alexa from Amazon (Ale 2020) can be framed weak AI as their operations is limited to a predefined range of functionalities. Basically, pre-trained models search for patterns in a recognized audio sample and classify the spoken words accordingly in both cases.
However, the mentioned two intelligent agents only react to stimuli which they were trained on and show some pre-defined reaction. So far, these kind of programs do not understand or deduce any meaning from what has been said in a wider sense, which marks the difference to strong AI. Strong AI, on the other hand, is supposed to act in a similar way to a human being. It should be noted, however, that while strong AI can act operatively like a human being, it is likely to have a completely different cognitive architecture compared to the human brain and will have different evolutionary cognitive stages (Bostrom 2017; Frochte 2019).
With strong AI, machines can actually think and perform tasks independently, just like humans do. In conclusion, strong AI-controlled machines have a “mind of their own” in a certain way. Accordingly, they can make independent decisions and process data, while weak AI-based machines can only simulate or mimic human behavior. Today, we are still in the age of weak AI, where intelligent behavior aims to do a specific task particularly well or even better than humans would do.
However, there are more and more efforts by tech giants from the Silicon Valley in California to create AI systems that not only perform a specific task, but solve a wider range of problems and make generalizations about a specific problem. Since the field of strong AI is still in its infancy, only weak AI and its components are described in more detail and used within this article. Further details on the historic development of AI and its definition in weak and strong from or neat and scruffy philosophy for AI are skipped at this stage with reference to (Goodfellow et al. 2016; Brownlee 2011; Chowdhary 2020).
Problem formulation
Models and algorithms are essential building blocks for the application of AI to practical problems, where an algorithm is defined as a set of unambiguous rules given to an AI program to help it learn on its own. (Mitchell 1997; Frochte 2019) defines a computer program to learn “from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.”
This definition allows for a wide variety of experiences E, tasks T, and performance measures P. However, in the remainder of this paper, intuitive descriptions and examples (Sect. 3) of different kind of tasks, performance measures, and experiences are introduced to construct machine and deep learning algorithms. At this point, some more details on task T and performance P as well as the role of data are given.
Before going into detail on T and P within this section, we elaborate further on the experience E and the role of data for AI, ML and DL. E is an entire dataset D, whose elements are called data points (or examples (Goodfellow et al. 2016)). A data point or example consists at least of features x∈Rn, where a feature is an individual measurable property or characteristic of a phenomenon being observed (Bishop 2006; Kuhn and Johnson 2013). The concept of a feature is closely related to what is known as “explanatory/independent variable” in statistical techniques such as linear regression.
Furthermore the features of E may be split further to separate targets/labels yy among the remaining features xx, where an AI algorithm is used to uncover relationships between the remaining features and the target of the dataset in case of more specific tasks such as supervised ML and many DL problems. As an example, when using an AI algorithm for linear regression, the task T is to find a function f:Rn⟶Rm, the model y=f(x) assigns an input (feature) vector x to the target vector y. Finally, AI models or algorithms may possess hyperparameters, which are tunable entities of an AI algorithm [such as regularization strength (cf. Sect. 2.1.3) or depth of a neural net (cf. Sect. 2.3)] and have to be investigated during the learning or training phase using a learning algorithm to train and evaluate the best model (Raschka 2018).
Data
To be able to process data in a meaningful way, it must first be collected and, if necessary, refined or pre-processed (Frochte 2019; Bishop 2006; Goodfellow et al. 2016; Mitchell 1997; Brownlee 2016; O’Leary 2013). According to (Frochte 2019; García et al. 2016) five quantities can be used to characterize a dataset:
- volume: amount of data
- velocity: rate information arrives
- variety: formats of data (structured, semi-structured, or unstructured)
- veracity: necessity for pre-processing procedure
- value: relevance of data for task T
While the first three aspects “volume, velocity, and variety” refer to the generation of data, capturing and storage process, “veracity” and “value” aspects mark the quality and usefulness of the data to the task T under consideration and hence are crucial for an extraction of useful and valuable knowledge from the data. If all five concepts of the proposed list are given to a certain extend, the definition of “big data” is met, which is of partial interest for this publication as will be explained in Sect. 3. From a technical point of view, the term “big data” (which may be auto-associated with AI by the reader) refers to large and complex amounts of data which require “intelligent methods” to process them. At this point more detail on the variety of data is given. Structured data is information, which has a pre-defined data model (Frochte 2019; O’Leary 2013; Rusu et al. 2013), i.e. the location of each part of the data as well as the content is exactly know.
Semi-structured data is a form of structured data that does not conform with the formal structure of data models associated with relational databases or other forms of data tables, but nonetheless contains markers to separate semantic elements and enforce hierarchies of records and fields within the data (Frochte 2019; Rusu et al. 2013).
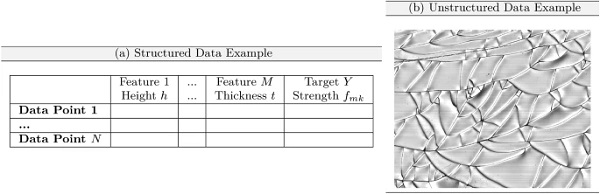
Finally, unstructured data is information that either does not have a predefined data model or does not fit into relational tables, (Frochte 2019; Rusu et al. 2013). Typical examples of structured data are databases or tables, while videos or pictures are classic examples of unstructured data and further illustration of data structures are given in Fig. 2.
While for structured data, the feature definition is mostly straight forward due to the structure (Turner et al. 1999; Brownlee 2016), feature generation (i.e. defining features) for unstructured data is essential and the process is also known as feature engineering (Ozdemir and Susarla 2018). Per se, the volume of data typically can be tackled with state of the art AI algorithms, whereas a huge number of features may become problematic (where it is often referred to as curse of dimensionality (Frochte 2019; Bishop 2006) and one of the main tasks here is to elaborate a discrimination into relevant and irrelevant features (Goodfellow et al. 2016; Frochte 2019; Bishop 2006; Kuhn and Johnson 2013). In order to tackle that issue, dimensionality reduction as well as feature selection techniques can be performed in order to reduce and/or select features according to their relevance for describing the task. More details on that will be given in the ML section of this paper or can be found in (Kuhn and Johnson 2013; Brownlee 2016; Bishop 2006).
At this stage some final notes on data types encountered in the field of structural glass engineering are given. In this specific field, information generally can be expected to be either way (structured, semi-structured and unstructured data), depending on the specific glass-related problem under consideration. In Sect. 3, it is elaborated that unstructured data in the form of photographic data is used for quality inspection and production control, whereas structured data in form of simulation data from numerical mechanical investigations or experiments is used to infer about patterns or model parameters by an AI algorithm. It is known from literature that the combination of the given data set and structure together with appropriately selected AI algorithms provides meaningful results (Goodfellow et al. 2016; Frochte 2019; Bishop 2006).
Simulation data mining is of particular interest for the numerical investigations within structural glass engineering (Brady and Yellig 2005; Burrows et al. 2011; Frochte 2019). Simulation of data in the field of structural glass engineering is on the one hand often expensive as simulations quickly become both theoretically and numerically evolved (and thus the whole dataset comprehends of just a few observations). On the other hand (e.g. in the case of a Finite Element simulation) the number of features and targets per simulation example may be great in number. This poses hardware requirements along with the need for a feature selection or engineering strategy. Experimental data on the other hand usually consist of a limited (small) number of observations together with a small amount of features due to monetary reasons and the design of the respective experiments (Kraus 2019).
As a conclusion, for the practical application of AI to problems in the glass industry the final choice on algorithms has to be made on a case by case basis depending on the task T and the volume, variety and veracity of the data.
Model and loss function
A task T is the description of how an AI should process data points. An example of a task T is to classify images of test specimens into “intact” and “failed”. The performance measure P evaluates the abilities of a AI algorithm and often P is related to specifics of the AI task T. To continue the previous classification example, a possible performance measure P is the accuracy of the classification model, where accuracy is the proportion of examples for which the model produces the correct output (Goodfellow et al. 2016; Brownlee 2011; Mitchell 1997). The choice of a proper performance measure is not straightforward and objective but dependent on the problem at hand and is thus a solid part of the model building part. As this paper is concerned with ML and DL examples only, the task T involves a mathematical model M.
When expressing the performance measure P in mathematical terms together with the notion of learning, the AI algorithm will update a mathematical model such that for given experience E better performance P is gained. This gain measured via P is conducted via (numerical) optimization, thus alternative nomenclature in ML or DL contexts may call P the “objective, loss or cost function” C. This paper adopts the notation of (Goodfellow et al. 2016), where from a mathematical point of view, a “function we want to minimize or maximize is called the objective function, or criterion”. Especially if the mathematical model M of an AI algorithm possesses parameters θ and learns from training on the data set (or short: data) D, this is formulated as the minimization of a cost function C:
![]()
where typical examples of cost functions C are
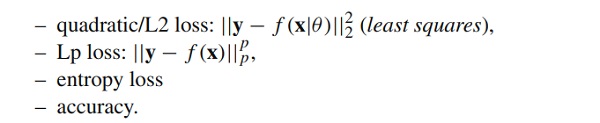
It is explicitly emphasized that the definition of the loss function is part of the model building process within the AI algorithm and will influence the training results to great extent (Goodfellow et al. 2016; Bishop 2006; Frochte 2019). In addition, for the same T task, multiple loss function choices may be useful for monitoring model performance, but there is no guarantee that they will result in the same set of optimal model parameters.
Data splitting
After possible cleansing and visualization of the data, different AI models are evaluated. The main objective is to obtain a robust AI model with a good ability to generalize well the extracted knowledge to data, which were not used during training the model by the learning algorithm (Mitchell 1997; Goodfellow et al. 2016; Bishop 2006).
This means that at the end of the training process, the final model should correctly predict the training data, while at the same time it should also be able to generalize well to previously unseen data. Poor generalization can be characterized by overtraining or overfitting (cf. Sect. 2.1.5), which describes the situation that the model just memorizes the training examples and is not able to give correct results also for patterns that were not in the training dataset (Mitchell 1997; Goodfellow et al. 2016; Bishop 2006; Frochte 2019). These two crucial demands (good prediction on training data as well as good generalization abilities) are conflicting and also known as the Bias and Variance dilemma (Bishop 2006; Frochte 2019). In order to judge how well a ML or DL model performs on data, there exist several types of methods for evaluation (i.e. validation) (Raschka 2018):
- holdout validation
- k-fold cross validation
- stratified K-fold cross validation
- leave-one-out cross validation (LOOCV)
The simplest method for validation is holdout validation, in which the data set is split into training and testing data over a fixed percentage value (Goodfellow et al. 2016; Frochte 2019). Using the holdout method is perfectly acceptable for model evaluation when working with relatively large sample sizes (Raschka 2018).
Nevertheless, it was shown that the three-way holdout validation in particular offers advantages. In the three-way holdout method, available training data may be split such that an additional validation dataset is formed (Russell and Norvig 2020; Bishop 2006). To be more specific, the three data sets are used as follows:
- training dataset: used to fit the model M (70% of |D|)
- validation dataset: used to provide an unbiased evaluation of a model M fit on the training dataset while tuning model parameters (20% of |D|)
- testing dataset: used to provide an unbiased evaluation of a final model fit on the training dataset (10% of |D|)
All data in the three sets should have a similar distribution for the entire set to ensure that the data are from the same distribution and are representative. Common choices for the sizes of the amount of data (here |D|≡N is the number of data points within the whole training set) are given in the bullet point list (Frochte 2019; Bishop 2006).
To tackle the problem of so-called over- and underfitting (i.e. the poor generalization capability of the AI model, cf. Sect. 2.1.5) cross validation (CV) may be applied for hyperparameter tuning and model selection. CV is a validation technique for assessing how the results of a statistical analysis will generalize to an independent data set (Raschka 2018). The k-fold cross validation for example has a single parameter k, which refers to the number of groups into which a given data sample is divided. As such, the procedure is often referred to as k-fold cross validation, where the k is replaced with the specific choice to form the concrete name (e.g. k=10 becomes a 10-fold cross-validation as depicted in Fig. 3).
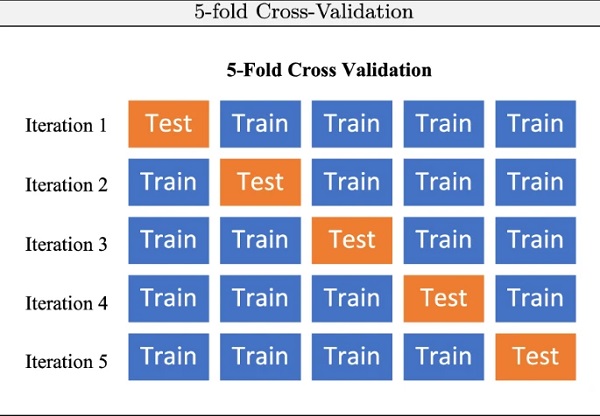
In contrast, splitting the data into folds can be controlled by criteria such as ensuring that each fold contains the same proportion of observations with a certain categorical value. This is called stratified cross validation.
However, if a small dataset with a feature count of less than 100 is owned, it has been shown that LOOCV provides good results for the accuracy and robustness of the AI models. This approach omits one data point from the training data, i.e. if there are n data points in the original sample, then n−1n−1 samples are used to train the model and p points are used as a validation set. This is repeated for all combinations where the original sample can be separated in this way, and then the error is averaged for all trials to obtain the overall effectiveness. The number of possible combinations is equal to the number of data points in the original sample or n and hence might be computationally expensive in the case of a large dataset.
Finally, if the readers are interested in detailed description on different techniques for data splitting, hyperparameter tuning, model selection and final deployment of machine learning models, (Raschka 2018; Bishop 2006; Reitermanova 2010; Frochte 2019; Goodfellow et al. 2016) provide detailed and comprehensive reading for that essential subject.
Over- and underfitting
Two central challenges in learning an AI model by learning algorithms have to be introduced: under- and overfitting.
A model is prone to underfitting if it is not able to obtain a sufficiently low loss (error) value on the training set, while overfitting occurs when the training error is significantly different from the test or validation error (Frochte 2019; Bishop 2006; Goodfellow et al. 2016). The generalization error typically possesses an U-shaped curve as a function of model capacity, which is illustrated in Fig. 4.
Choosing a simpler model is more likely to generalize well (having a small gap between training and test error) while at the same time still choosing a sufficiently complex hypothesis to achieve low training error. Training and test error typically behave differently during training of an AI model by a learning algorithm (Frochte 2019; Bishop 2006; Goodfellow et al. 2016). Having a closer look at Fig. 4, the left end of the graph unveils that training error and generalization error are both high. Thus, this marks the underfitting regime. Increasing the model capacity, it drives the training error to decreases while the gap between training and validation error increases. Further increasing the capacity above the optimal will eventually lead the size of this gap to outweigh the decrease in training error, which marks the overfitting regime.
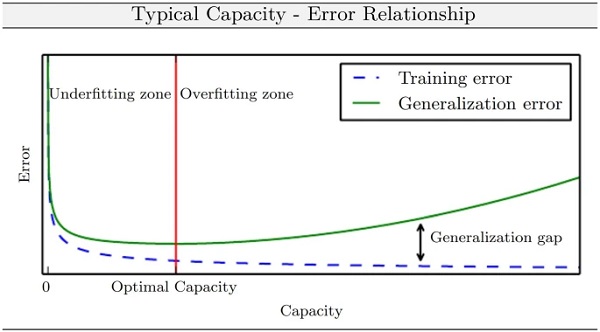
Increasing model capacity tackles underfitting while overfitting may be handled with regularization techniques (Frochte 2019; Bishop 2006; Goodfellow et al. 2016; Kuhn and Johnson 2013). Model capacity can be steered by choosing a hypothesis space, which is the set of functions that the learning algorithm is allowed to select as being the solution (Goodfellow et al. 2016). Here, varying the parameters of that function family is called representational capacity while the effective capacity takes also into account additional limitations such as optimization problems etc. (Goodfellow et al. 2016).
Trends for AI in the engineering and natural sciences
Recent developments in the field AI related to natural as well as engineering sciences formed the terms physics-informed/theory-guided AI, which is a field, where the authors of this paper are also active in, cf. Fig. 1b. The aim here is to achieve two goals:
- Compensate data sparsity.
- Utilize available theoretical knowledge in a formal way.
Training AI models with few data are at the center of knowledge inference in the natural and engineering sciences, in contrast to the typical structure of AI in economics or computer science, where very large amounts of data are available for the problem under consideration. The reasons for the sparsity of experimental or computational data may result on the one hand from the fact that they are expensive or the gathering of a great amount of those data is prohibitive due to time or financial constraints. On the other hand, the formal introduction and use of pre-existing and already existing theoretical knowledge (both from science and from experts), e.g. in the form of the loss function (Raissi 2018), leads to shorter familiarization times through meaningful previous starting points for optimization within the AI algorithms or the setting of boundary conditions to the parameters to be derived. Further information can be found in (Reichstein et al. 2019; Karpatne et al. 2017; Wagner and Rondinelli 2016; Raissi 2018; Kraus 2019).
Machine learning
Machine Learning is a sub-branch of AI, which is concerned with algorithms for automating the solution of complex learning problems that are hard to program explicitly using conventional methods. ML algorithms build a mathematical model MM to infer between quantities of interest (features; targets) based on data to make predictions or decisions without being explicitly programmed to do so (Frochte 2019; Rebala et al. 2019; Chowdhary 2020; Murphy 2012). This section provides a brief introduction to the most general principles and nomenclature, a more thorough introduction and elaboration on the subject is given in (Bishop 2006; Goodfellow et al. 2016; Mitchell 1997; Rebala et al. 2019; Murphy 2012).
A basic premise, however, is that the knowledge gained from the data can be generalized and used for new problem solutions, for the analysis of previously unknown data or for predictions on data not measured (prediction). As elaborated in the previous section on AI, ML also has strong ties to optimization as learning problems are typically formulated as minimization of some loss function on a training set of examples (Frochte 2019; Bishop 2006; Goodfellow et al. 2016; Murphy 2012). Furthermore ML (as well as DL) are closely related to statistics in terms of methods but differ in their goal of drawing population inferences from a sample (statistics) vs. finding generalization predictive patterns (Bzdok et al. 2018).
Two different main algorithm types can be distinguished for ML: supervised and unsupervised learning (Mitchell 1997; Bishop 2006; Goodfellow et al. 2016; Frochte 2019), which are briefly introduced here and graphically illustrated in Fig. 5 (Deep Learning is treated in the next subsection of this paper and Reinforcement Learning is omitted within this paper at all).
In ML, there is a data set
![]()
with N observations, where xn is the feature/influence variable and tn the target/response variable. Both variables can be continuous or discrete (categorical). While in supervised learning a predictive model M based on both influence and response variables is to be developed, in unsupervised learning a model is learned only on the basis of the features (clustering; dimension reduction). For supervised learning, a distinction is made between classification and regression problems. While in the former case the response variables tn can only take discrete values, the response variables tn are continuous for regression problems.
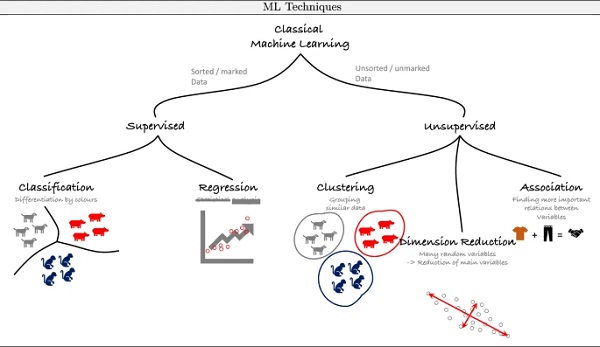
The goal of regression is to predict the value of one or more continuous target variables t given the value of a vector x of input variables, whereas the goal in classification is to take an input vector x and to assign it to one of K discrete classes Ck where k=1,…,K (Bishop 2006). A more detailed description of supervised ML models such as linear and non-linear regression or generalized linear model regression along with classification is omitted within this paper with reference to already mentioned ML textbooks. By using regression or classification models, it is furthermore possible to catch nonlinear and more complex dependencies between the in- and outputs. For further information it is referred to (Kraus 2019; Bishop 2006; Goodfellow et al. 2016; Mitchell 1997; Lee et al. 2018; Murphy 2012).
In Fig. 5 on the right hand side, the main categories of unsupervised learning algorithms are given. These algorithms use input data only to discover structure, patterns and groups of similar examples within the data (clustering), or to determine the distribution of data within the input space (density estimation), or to project the data from a high-dimensional space down to lower dimensions (Goulet 2020; Kraus 2019; Bishop 2006; Goodfellow et al. 2016; Mitchell 1997; Lee et al. 2018). Cluster algorithms use similarity or distance measures between examples in the feature space as loss functions to discover dense regions of observations (Hastie et al. 2009).
Clustering algorithms in contrast to supervised learning only use a divide-and conquer strategy to interpret the input data and find natural groups or clusters in feature space, where a single cluster is an area of density in the feature space where data are closer to the cluster than other clusters (Witten et al. 2016; Bishop 2006; Goulet 2020). Typical clustering algorithms are “k-means” (Lloyd 1982; Goulet 2020; Bishop 2006) and the “mixture of Gaussians” (Goulet 2020; Bishop 2006). Similar to clustering methods, dimensionality reduction aims to exploit inherent (latent (Bishop 2006; Goodfellow et al. 2016; Lee et al. 2018)) structure in the data in an unsupervised manner to reduce the number of features to a set of principal variables, where the approaches can be divided into feature selection and feature extraction (Roweis and Saul 2000; Bishop 2006). Fewer input dimensions (i.e. number of features) induce fewer parameters or a simpler structure in the ML model, referred to as degrees of freedom (Murphy 2012).
A model with too many degrees of freedom is likely to overfit the training dataset and therefore may not perform well on new data (Murphy 2012; Bishop 2006; Goulet 2020). Further details on typical algorithms such as “Principal Components Analysis (PCA)”, “Manifold Learning” or “Autoencoders” are skipped within this article with referencing the reader to (Murphy 2012; Bishop 2006; Goulet 2020; Witten et al. 2016; Frochte 2019).
A generally valid scheme of steps involved in a successful ML project is presented in Fig. 6.
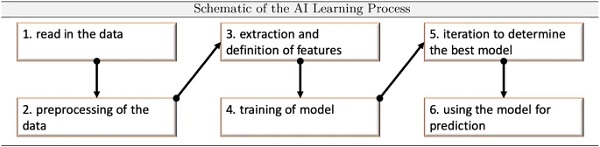
Different aspects of Fig. 6 are discussed at this point, as the conduction of every step is essential for building a sensible AI/ML application. In step 1 and 2 existing data are compiled and brought in a form that AI/ML model can access it and the learning algorithm is able to train the model on the present data. This step may take minutes to months in dependence of the problem and the data structure of the respective environment. Especially when digitizing existing older data from paper. It is advisable to consider standardization protocols for this step in order to guarantee data consistency within a company. It is however important to note that the predictive power and accuracy of any data-driven model is based on the accuracy and quality of the input data.
In the context of this paper, step 3 (feature extraction) will be briefly discussed, since this represents the interface between AI/ML and engineering on the one hand, and on the other hand it has a significant influence on the quality of the model’s statements and predictions. Different strategies for deriving features exist:
Historically, ML uses statistical features obtained by unsupervised learning methods (e.g. cluster analysis, dimensionality reduction, autoencoders, etc.), but as in the context of glass engineering thermomechanical as well as chemical models exist, the parameters of those equations may also serve as features. The number of features that can be derived from the data is theoretically unlimited, but some techniques are often used for different types of data.
For example, the task of feature selection is to extract certain signal properties from, for example, raw sensor data to generate higher-level information. Feature extraction techniques in this context are the detection of peaks, the extraction of frequency contents by Fourier transform, the identification of signal trends by sum statistics (mean and standard deviation at different experimental times), etc. Further details on the individual steps can be found in (Bishop 2006; Goodfellow et al. 2016; Chang and Bai 2018; Kraus 2019; Tandia et al. 2019; MAT 2016c, a,b).
Deep learning
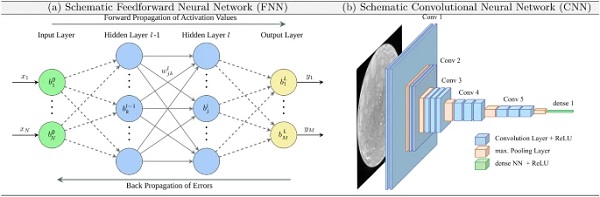
Deep learning is sub-field of ML (Goodfellow et al. 2016), which uses so-called artificial neural networks as models to recognize patterns and highly non-linear relationships in data. An artificial neural network (NN) is based on a collection of connected nodes (the neuron), which resemble the human brain (cf. Fig. 7). Today many of architectures of neural nets are known (Van Veen 2016), however in the context of this paper only the specific sub-classes of feedforward neural nets (FNN) and convolutional neural nets (CNN) are of interest, cf. Fig. 7. Details on the specifics of the various other types of NN can be found for example in (LeCun et al. 2015; Goodfellow et al. 2016).
Due to their ability to reproduce and model non-linear processes, artificial neural networks have found applications in many areas. These include material modeling and development (Bhowmik et al. 2019; Goh et al. 2017; Mauro 2018; Mauro et al. 2016; Elton et al. 2019), system identification and control (De la Rosa and Yu 2016; Rudy et al. 2019; Baumeister et al. 2018; Mosavi 2019), pattern recognition of radar systems (Chen and Wang 2014), face recognition (Hu et al. 2015; Sun et al. 2018; Li and Deng 2020), signal classification (Kumar et al. 2016; Fawaz et al. 2019), 3D reconstruction (Riegler et al. 2017), object recognition (Rani et al. 2020; Zhao et al. 2019), sequence recognition for gesture (Elboushaki et al. 2020; Gao et al. 2020), speech (Yu and Deng 2016; Nassif et al. 2019), handwriting and text (Zheng et al. 2015; Jaramillo et al. 2018), medical diagnostics (Bejnordi et al. 2017; Ker et al. 2017; Greenspan et al. 2016; Liu et al. 2019) and e-mail spam filtering (Guzella and Caminhas 2009).
The FNN is constructed by connecting layers consisting of several neurons, a schematic sketch is shown in Fig. 7. The first layer (0th) of the FNN is the input layer of dimension RN, the last layer (Lth) is the output layer, and the layers in between are called hidden layers (lth). A neuron is an operator that maps RK⟶R (with K connections to neurons from the previous layer l−1) and described by the equation:
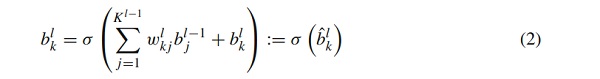
where σ(⋅) is a monotone continuous function and commonly referred to as activation function. The activation is computed as a linear combination of the neurons in the previous layer l−1 given the corresponding weights wlkj and biases blk of layer l, cf. Eq. (2) and Fig. 7. The choice of connecting the neurons layer wise is user dependent, if each neuron is connected to every neuron in the two neighbor layers, the FNN is called dense or densely connected. In summary, FNN represent a specific family of parameterized maps (depicted by ∘ for the composition operation), which are surjective if the output layer possesses linear activation function and can be expressed as:
![]()
where
![]()
(tensor notation) represents the data transform in one layer l. A neuron is a non-linear, parameterized function of the input variables (input neurons; green in Fig. 7). A NN is hence a mathematical composition of non-linear functions of two or more neurons via an activation function. This particular non-linear nature of NNs thus is able to identify and model non-linear behaviors, which may not at all or not properly be captured by other ML methods such as regression techniques or PCA etc. Despite the biological inspiration of the term neural network a NN in ML is a pure mathematical construct which consists of either feed forward or feedback networks (recurrent).
If there are more than three hidden layers, this NN is called a deep NN. The development of the right architecture for an NN or Deep NN is problem dependent and only few rules of thumb exist for that setup (Bishop 2006; Frochte 2019; Kim 2017; Paluszek and Thomas 2016). Convolutional (neural) networks (LeCun et al. 1995; Goodfellow et al. 2016) (CNN) mark a specialized kind of NN for processing data with grid-like topology. Examples include time-series data (1-D grid taking samples at regular time intervals) and image data (2-D grid of pixels).
In contrast to FNN, the CNN employ the mathematical operation called convolution, which is a special kind of general matrix multiplication in at least one of their layers. In addition to the convolution, a pooling operation is applied to the data between layers. This paper will not further elaborate on details on convolution operations and several pooling strategies along with training approaches for the different kinds of NN, instead the reader is referred to (Bishop 2006; Frochte 2019; Goodfellow et al. 2016).
Further well-known NN are recurrent neural networks (RNNs) for processing sequential data (Graves 2012; Goodfellow et al. 2016), autoencoder for dimensionality reduction or feature learning (Skansi 2018; Goodfellow et al. 2016) and many more, which are not subject of this paper. DL is a supervised learning strategy and may need a great amount of data for meaningful training, depending on the specifics of the problem at hand (Bishop 2006; Frochte 2019; Goodfellow et al. 2016).
This situation then may prohibit the use of DL for some applications in research and practice. In summary, model capacity in case of NN is greater compared to ML models in the sense, that the NN as function space allows for more variety than typical function spaces used in ML models. Thus all points raised in Sects. 2.1.3 to 2.1.5 require special considerations in the DL setting and hyperparameter tuning along with validation issues are essential for generalization NN models for successful application in the engineering context.
AI applied to structural glass and related fields
So far, an introduction on the basics and background on AI, ML and DL was given and some concepts for model building, training and validation were introduced. AI is a fast-growing technology that has now entered almost every industry worldwide and is expected to revolutionize not only industry, but also other social, legal and medical disciplines. Specifically the construction industry possesses the lowest rate of digitization (Chui et al. 2018; Schober 2020). Here new technologies are introduced hesitantly due to the long lifespan of building structures and associated reservations or concerns about the risks and reliability of new methods and products due to the lack of experience. However, considering that about 7 % of all employees worldwide work in the construction sector, there is a considerable market potential in the development and transfer of new approaches from AI to this sector (Schober 2020).
Focusing now on structural glass and façade construction within the whole building industry, this branch is, in contrast to more established branches such as concrete or steel construction or bridge design, relatively progressive, innovative and open to technology. This can be demonstrated by numerous projects in the field of façade constructions, such as the use of adaptive façade elements in the building envelope (Shahin 2019; Romano et al. 2018), switchable glass as sun protection (Marchwiński 2014; Vergauwen et al. 2013), numerical modeling of complex adhesively bonded façade elements (Drass and Kraus 2020a), the consideration of time and temperature dependent material behavior of polymeric interlayers in laminated glasses in the intact and post-failure state (Kraus 2019), or the parametric design of building envelopes (Wang and Li 2010; Zhang et al. 2019; Granadeiro et al. 2013; Vergauwen et al. 2013).
Within this section, the focus is on structural glass and façade construction within the building industry. In the remainder of this paper different areas of interest for the application of AI are identified, potentials and possibilities are uncovered and outlooks to future visions are highlighted. In order to characterize the special flavor of the needs and potentials of applying AI to this specific field of design, engineering and products, the authors created the term “Artificial Intelligence for the Building Industry (AI4BI)”.
AI has yet been applied in engineering (Quantrille and Liu 2012; Patil 2016; Bunker 2018), economy (Varian 2018), medicine (Szolovits 2019) and other sectors for modeling, identification, optimization, prediction and control of complex systems and/or components thereof (De la Rosa and Yu 2016; Rudy et al. 2019; Baumeister et al. 2018; Mosavi 2019). Some review articles compile the state of the art of AI in civil engineering as a whole discipline (Huang et al. 2019; Patil et al. 2017; Lu et al. 2012; Adeli 2001) while a huge number of publications deal with specific problems from the civil engineering field (which in part were already cited so far in this paper), which are not given explicitly here in order due to reasons of brevity. However, especially for the structural glass engineering context a review paper has not yet been published, which is partially the intention of this contribution. Table 1 gives an overview of present examples on applying AI in structural glass engineering as discussed and firstly presented in this paper.
Table 1 Overview and summary table of the examples of this paper on the application of AI in structural glass engineering and related disciplines - Full size table
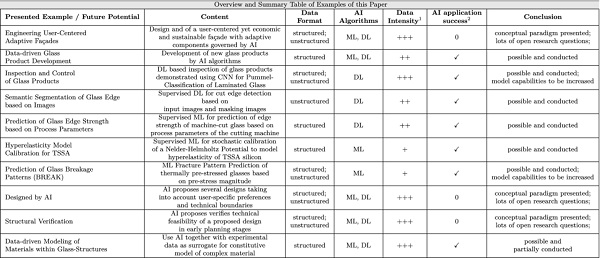
In the remaining section, the examples will always be elaborated according to the scheme of describing the problem, explaining the traditional engineering solutions, elaborating new possibilities and added value due to using AI and judging challenges and difficulties related to this approach.
AI for engineering user-centered adaptive façades
The topic of the building envelope or façade has gained enormous importance in recent years due to the discussion on sustainability and energy saving (Aznar et al. 2018), where lately the consideration of the user health, well-being, productivity and interaction with the building/façade was added (Luna-Navarro et al. 2020). The building envelope on the one hand side determines design and perception of the building for both users and the public while on the other hand, the building envelope is a significant structural sub-system for occupant comfort and interaction of the user with the environment of the building. Interaction of the user with the envelope so far was either mainly driven by manual and local personal control (e.g. through opening a window or drawing a curtain) or semi-automated by triggered predefined sequences leading to actions (e.g. switchable and smart glazing, dynamic shading) (Day and O’Brien 2017).
This led to the situation of occupants often being dissatisfied even in the scenario with control strategies and related interactions with automated systems (Luna-Navarro and Overend 2018; Fabi et al. 2017; Borgstein et al. 2018; Day and O’Brien 2017; Bluyssen et al. 2013; Meerbeek et al. 2014). Automation of the building in a combination with AI is a promising solution for low-energy buildings through a data-driven yet occupant-informed approach consisting of actuation systems and ubiquitous sensing devices steered by learning AI algorithms. Concepts so far are concerned with a proper design (structural, serviceability, sustainability, user well-being) and adaption of façades but dismissed the aspects of health monitoring as well as structural design requirements for adaptive structures over the lifespan of the envelope (cf. Fig. 2 in (Aelenei et al. 2016) on the characterization concepts of adaptive façades, where structural aspects are assumed to be per-fullfilled), which are introduced and discussed within this section.
Within this article, three major points for the application of AI in the façade engineering context are highlighted:
- multi {physics; user} constrained design by/through AI
- data-driven {structural adaptivity; health monitoring; predictive maintenance}
- intelligent functional {façade; home; office building}
Driving the multi {physics; user; verification code} constraints for AI in the façade
Basic design principles for civil engineering structures enforce very stringent safety and serviceability criteria which assume extreme loading and resistance situations, which occur with very low probabilities, hence these structures are over-designed for most of their service lives (Akadiri et al. 2012; Senatore et al. 2018). The structural adaption philosophy on the other hand reduces material and energy consumption of the building construction through a paradigm of controlling strength and stiffness in real-time via sensing and actuation to carry the acting loads (Wada 1989; dos Santos et al. 2015; Wagg et al. 2008; Fischer et al. 2009). Over the last couple of years several adaptive façade systems were researched. On the one hand side a “structure focused” branch considered either shaping façade elements (e.g. thin glass) (Amarante dos Santos et al. 2020; Silveira et al. 2018; Louter et al. 2018) or enabling rigid façade-components to be adaptive (Schleicher et al. 2011; Svetozarevic et al. 2019) while diminishing sustainability and comfort.
On the other hand a “sustainability and user-centered” branch considered strategies for either predefined levels of sustainability, energy saving and user comfort by design or allowed for user-control strategies to address occupant-building-interaction in addition to sustainability concerns. Taking into account the statements of this and the preceding paragraph leads to the conclusion, that adaptive façades have to be modeled as a multi-criteria optimization problem with highly nonlinear and imprecise (in the fuzzy sense; for user/occupant modeling) correlations, which a priori may not be known to a certain extend (especially the user well-being part of the equation) or have to be “learned” from data of experiments (e.g. multi-occupant requirements; features from multi-sensor measurements).
For the design stage AI and ML can be used to infer suitable technical solutions to given tasks under consideration in an early design stage (AI assisted design and planning) with a potential check for planning errors or unlikely verification success of the designed solution. The main problem for an immediate introduction and application of AI here is the low digitization rate (Chui et al. 2018; Schober 2020) (especially details for older buildings are highly likely documented on paper rather than in a digital ML readable format), the high variation of data formats (CAD formats, formats of structural verification software, etc.) within the design, planning and verification process in civil engineering and the heterogeneity of associated partners (usually small companies with no formal protocol on a digital workflow) in a design and construction project. Furthermore due to keeping competitive advantages many companies do not want to share or make publicly accessible technical solutions in form of a database.
Steps towards AI in façade engineering
A fully digital workflow upon the Building Information Modeling (BIM) (Borrmann et al. 2015; Isikdag 2015) approach for the whole life cycle of a building solves the digitization problem and allows AI algorithms to be applied in several forms. BIM is a digital description of every aspect of a construction project and nowadays practiced to some extend in the construction industry. The initial idea of BIM is a 3D information model formed from both graphical and non-graphical data, which are compiled in a shared digital space called (Common Data Environment; CDE). All information on that specific building is constantly updated as time progresses during the life cycle of a building and thus ensures the model to always be up-to-date (Serrano 2019).
However, BIM today still suffers from technical challenges across disciplines such as architectural design, structural verification, building physics design, maintenance measurements etc. and a full digital workflow with AI components from the early first sketches to demolition of a building (Ghaffarianhoseini et al. 2017; Vass and Gustavsson 2017; Akponeware and Adamu 2017) is not yet possible. For the application of AI in that multi-criteria optimization and control problem as described earlier in this section, there is need of a cyber-physical twin (digital twin, computable structural model) (Boschert and Rosen 2016; Borrmann et al. 2015; Raj and Evangeline 2020) within the life cycle-accompanying BIM paradigm.
The digital twin is a digital image of a physical system which is heavily used in industry so far to reduce operational errors and optimize product design. The starting point for a digital twin is a highly accurate three-dimensional model that contains all the features and functions of the physical system, including material, sensor technology or even dynamics of the real structure. The parametric design approach in architecture (Monedero 2000; Wortmann and Tunçer 2017; Oxman 2017) is a first step in these directions and seems very suitable for a connection to AI as it currently uses optimization algorithms, e.g. genetic algorithms etc. which are are sub-groups of AI.
Due to the fact that structural verification is solidly based on mechanics and theory, the application of AI in the verification stage during design of structures is very likely to be successful as through mechanics it is guaranteed to hit a certain solution manifolds of the problems which itself induces manifolds of feasible design solution (which is in contrast to the view of data analysis, where there is a priori no knowledge of the process by which data is created). First experiences with automating design reviews with AI in a BIM context is delivered by (Sacks et al. 2019), where building models are checked for conformance to code clauses of simple form (explicit formulations; implicit and complex clauses are still beyond the scope of such applications).
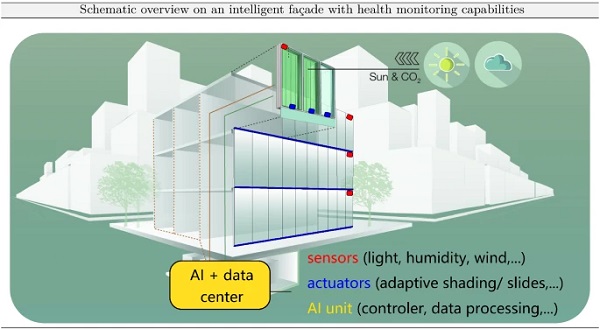
The combination of health monitoring/predictive maintenance and an intelligent façade/home/building are schematically visualized in Fig. 8 and can be implemented within one and the same façade project. The reason for distinguishing these two situations is due to the fact, that the deployment is in dependence of the needs of the building owner or user (cf. comments on multi-criteria optimization problem earlier in this paragraph) and both systems work individually on a partly shared data basis (cf. comments on BIM and the digital twin earlier in this paragraph). Especially for the situation with existing façade structures the retrofitting with both systems may be prohibitive due to monetary reasons. However, in buildings to be designed and constructed from scratch, an integrated approach implementing the two functionalities can be considered. In the remainder of this subsection, some background and potential realization outlooks are given.
Both mentioned ideas are rooted in the data-driven approach to identification, control and steering of structural systems. There, ML is a rapidly developing field that is transforming the ability to describe complex systems from observational data rather than first-principle modeling. While for a long time, ML methods were restricted to the application to static data, more recent research concentrates on using ML to characterize dynamical systems, (Brunton and Kutz 2019). Especially the use of ML to learn a control function, i.e. to determine an effective map from sensor outputs to actuation inputs is most recent. In this context, ML methods for control include adaptive NN, genetic algorithms and programming and reinforcement learning.
The second mentioned issue for an intelligent façade or building is similarly treatable form a mathematical and AI point of view (Aznar et al. 2018; Luna-Navarro et al. 2020). Similar ML methods apply in this context as well. The overall idea is that given a reasonable and suitable loss function, i.e. a function, which is able to correctly describe the well-being and comfort of a user, the façade or building is able to learn the specific domain of comfort for the individual user by training an AI algorithm for a reference state and continuous user feed back about the well-being. Through that approach, it will be possible to provide maximum user comfort with minimal invasiveness.
If supervised ML or DL algorithms are applied, a loss function (characterizing the control and steering problem) has to be established in the mentioned contexts. In addition the development of suitable and meaningful features, which allow a structurally sensible and unambiguous classification of the condition of the façade under consideration, is necessary (Aznar et al. 2018; Luna-Navarro et al. 2020). For example, the construction-physical principles and interrelationships for describing the comfort of the user as a result of external influences and their manipulation, e.g. by controlling the light-directing or heating systems, are already known today in theory, but to date these have not been taken into account in any approach to the “smart home”.
This is particularly due to the fact that (analogous to the “Internet of Things”) mechanical engineering in particular has so far been concerned with the networking of machines and devices without incorporating the knowledge specific to civil engineering with regard to the interaction of people and buildings. An AI can be extended here by building physics criteria and evaluate the user data in such a way that a building (living space/work use) learns the preferences of the respective user over time via the diverse data streams and adapts to the user. This idea goes far beyond the currently existing approaches of “smart home”, so that a conceptual delimitation of the “intelligent home/office” becomes obvious.
Similarly, structural features, such as deflections or accelerations, may serve as sensible features together with some signal statistic features to describe well the structural behavior of a monitored façade under control of an AI. In the health monitoring situation, additional information has to be given to the AI algorithm in order to enable it to predict the remaining lifetime or inspection intervals, which is known in mechanical engineering as predictive/prescriptive maintenance (Brunton and Kutz 2019). In order to make the nomenclature clear, predictive maintenance employs sensors data to precisely collect data describing the conditions of an asset and overall operational state.
The data are then analyzed for prediction of future failure events and their occurrence times. Prescriptive maintenance takes this analysis to a further state of maturity as it not only predicts failure events but also recommends actions to take and when. The structural health monitoring (SHM) thus predicts the future performance of a component by assessing the extent of deviation or degradation of a system from its expected normal operating conditions (NOC) (Brunton and Kutz 2019). The inference of the NOC is based on the analysis of failure modes, detection of early signs of wear and aging and fault conditions.
This is the bottleneck of the AI approach to façade monitoring, as it is necessary to have initial information on the possible failures (including site, mode, cause, and mechanism), which for new façade systems can only be learned “on the fly” after installation of the façade. However, with a data-driven approach, a certain initial training phase (e.g. 5 years) can be implemented as a training and identification period for the AI to learn the NOC and to detect derivations of it (Fig. 9).
Concluding this paragraph, AI together with a BIM-embedded digital twin has the potential to enhance the built environment with occupant interaction to form sustainable intelligent buildings and façades and hence deliver satisfying human-centered environments. However, more research is needed to build the multi-criteria loss function for the AI control system via a holistic and multidisciplinary approach.
AI in glass product development, production and processing
Glass and façade construction is highly technological in the area of industrial development, production and further processing of glass, as glass is a brittle material and inferior quality in processing can lead to fatal events in their assembly, construction and/or operation (Schneider et al. 2016; Sedlacek 1999; Siebert and Maniatis 2012). Consequently, high-precision machines are used for glass production and processing to enhance the brittle material in such a way that it exhibits high qualities.
Starting from washing the glass, cutting and breaking, thermal/chemical tempering and lamination to form a laminated (safety) glass (Schneider et al. 2016; Sedlacek 1999; Siebert and Maniatis 2012). The machine technology for glass refinement is constantly being improved and optimized to meet customer-specific requirements. Currently available established methods either fail or are worse in comparison to AI technologies, which can be integrated here. The following examples elaborate in more detail the use of AI for faster and more systematic improvements in production and manufacturing of glass products. Within this section, four different applications of AI for production and quality management of glass are highlighted:
- Glass Product Development
- Inspection and Control of Laminated Glass
- Semantic Segmentation of Cut Glass Edges
- Strength Prediction based on Cutting Process Parameters
AI for data-driven glass product development
Today, there is increasing demand on highly-functional, manufacturable and inexpensive glasses (Tandia et al. 2019), which has led glass researchers to use data-driven machine learning models to accelerate the development of glasses and glass products instead of traditional trial-and-error approaches. In this context, data-driven materials discovery approaches use statistical models as well as ML algorithms, which are trained, tested, and validated using materials databases. An important part of this approach is to develop or access accurate materials databases at low cost.
While it is in principle possible to use first principles approaches (thermochemical/thermodynamical simulations such as ab initio calculations based on quantum mechanics, density functional theory, molecular dynamics, or lattice models etc. (Van Ginhoven et al. 2005; Benoit et al. 2000)) to compute electronic band structure, formation energy and other thermodynamic parameters, the computations for technical products and an estimation of the properties by these methods still are prohibitively expensive and time consuming. From a mathematical point of view, composition of the design of new glasses can be seen as a multi-objective optimization problem with many constraints, which can be easily handled by an ML approach. (Hill et al. 2016)
Having at hand significant computing capabilities, data-mining algorithms, an efficient data storage infrastructures and an (publicly) available materials database enables researchers to discover new functional materials by AI within significantly lower temporal and monetary efforts than in conventional processes. The development of new products by data-driven AI methods relies on the establishing or existence of accessible databases, which in practice hardly exist for the public but do on the level of individual companies or research groups. A very mature compilation of publicly available materials databases for model and glass product development is given in (Tandia et al. 2019).
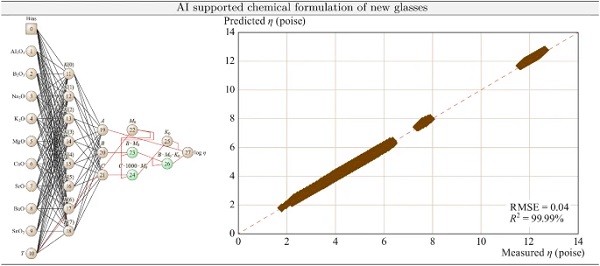
An example for the data-driven development of a new type of glass is shown in the following, which was presented by (Tandia et al. 2019). In that example, the two most important properties for glass design are liquidus temperature TL and viscosity η, where the glass liquidus temperature is defined as the temperature at which the first crystalline phase precipitates from the melt of a given glass composition when the melt is cooled with very small rate and the viscosity is relevant for the targeted sheet thickness in the production phase. Still today no accurate and generalizable physics-based models for glass melt liquidus temperature or melt viscosity for industrial glasses is known, thus the application of DL is a viable strategy for the development of a predictive model for both liquidus temperature and viscosity.
Among other ML techniques, a NN is trained for the prediction of both parameters, which is presented in more detail within the context of this paper. The NN as well as the predictive capabilities are shown in Fig. 10. Due to reasons of brevity, only the AI modeling of the viscosity η is described in detail, as this quantity drives the glass thickness within the production process. In the approach of (Tandia et al. 2019), the MYEGA model was used in combination with a NN. The MYEGA model possesses the form:

in which A is negative while B and C are positive constants. A Bayesian optimization (BO) framework was used for inference of the model parameters (number of layers, number of neurons in each layer, learning rate, activation function etc.).
It was found, that the combined NN-MYEGA equation approach resulted in a sufficiently accurate prediction model with low error in the validation set compared to other models and thus the development of new glass compositions was possible within significantly lower time at less money. Further details on this specific example can be found in (Tandia et al. 2019) while (Mauro et al. 2016; Mauro 2018) provide further application cases of AI for glass material development.
AI for inspection and control of glass products
Building products and pre-fabricated building components currently have to full fill certain national and international standards to ensure a minimum level of reliability and uniformity of these products across nations (Schneider et al. 2016; Siebert and Maniatis 2012). New production technologies such as additive manufacturing together with new strategies for achieving the requirements of building regulations demand automation of material quality testing with little human intervention to ensure repeatability and objectivity of the testing process.
In the status quo of quality control of glass and glass products, visual inspections are often carried out by humans to evaluate, for example, the cleanness of the glass, the quality of cut edges (Bukieda et al. 2020), anisotropy effects caused by thermal tempering of glass (Illguth et al. 2015) or to determine the degree of adhesion between interlayer and glass (Franz 2015). In these existing testing protocols, the assessment and judgment of a human tester is required to quantify the degree of reaching requirements of building regulations, hence the human quality quantification results are prone to non-negligible statistical uncertainty through the human tester decisions, (Wilber and Writer 2002).
Applying AI in the field of production control of glass and glass products hence seems promising for reaching above-human level accuracy in quality inspection based on objectification, systematization and automation. This approach was already proved successful in related scientific fields involving AI and especially DL for computer vision (i.e. how computers can gain high-level understanding from digital images or videos), where it clearly outperformed humans in several areas (Voulodimos et al. 2018; Ferreyra-Ramirez et al. 2019).
Visual inspections for quality management are typically organized in an inspection process (determined in many cases by national or international building regulations), which probes the whole production process through several human-based controls of product-specific quality measures. Since humans in principle are unable to provide an objective result of a quality control due to their own bias (Nordfjeld 2013), uncertainty in objectification and repeatability of the quality measures is induced. It is thus preferable to supply a technological solution in the form of combining AI and computer vision to automate the quality inspection while minimizing human intervention.
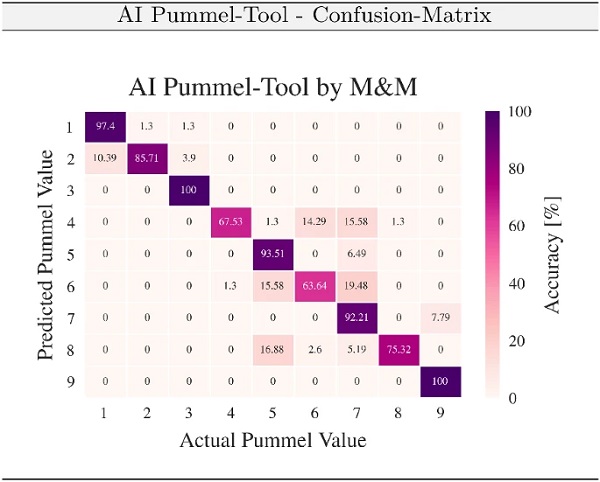
Within the scope of this paper an example for the objectification, systematization and automation of a visual product inspection for laminated glasses by the so-called Pummel test is presented. The Pummel test specifically characterizes the degree of adhesion between the polymeric interlayer and the glass pane of a glass laminate, where an optical scale ranging from 0 to 10 characterizes the level of adhesion. The resulting Pummel value thus delivers an indicator for the quality and safety properties of laminated glass, where a value of 0 quantifies no adhesion and 10 very high adhesion (Beckmann and Knackstedt 1979; Division 2014).
The laminated glass specimen for the Pummel test consist of two float glass panes with a maximum thickness of 2 × 4 mm. The specimens are exposed to a climate of −18∘C for about 8 h and subsequently get positioned on an inclined metal block and processed with a hammer (pummel). The Pummel value is then estimated by a human inspector based on the surface area of polymer interlayer exposed after pummeling (cf. Fig. 11-left). Further details on the Pummel test can be found in (Schneider et al. 2016; Beckmann and Knackstedt 1979; Division 2014).
Traditional image-based computer vision methods for evaluating the Pummel test extract image features using complex image pre-processing techniques, which in the experience of the authors based on conducted investigations on Pummel test pictures so far marked the main difficulties with these approaches. On the one hand, the proper choice of a performance metric on the pummel images (e.g. certain quantiles of the cumulative distribution function of grey-values or full color spaces of the images), which is invariant under the widely varying real-world situations for taking such a Pummel image with thin cracks, rough surface, shadows, non-optimal light-conditions in the room of pummel inspection etc., is demanding and led to no clear favorable function.
On the other hand, the access to just a limited amount of labeled training image data formed another obstacle. To address these challenges, this paper proposes an AI-based classification tool (AI-Pummel Tool), which uses a deep convolutional neural network on grey-value images of pummeled glass laminates to completely automate pummel evaluation while excluding human bias or complex image pre-processing.
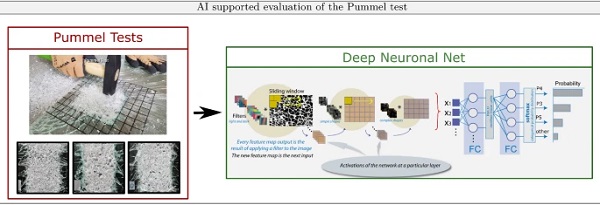
Following the data-driven approach of AI, in Fig. 11 a schematic illustration of the workflow for an AI-based automated pummel classification is given. It relies on the input of grey-value images after pummeling the laminated glass. These pictures are then processed by a pre-trained deep CNN for classification into one of the 11 Pummel value categories. Details on the principal architecture of CNNs were already given in Sect. 2.3, further details on CNNs especially within the field of computer vision are not described here in detail with reference to (LeCun et al. 2015; Voulodimos et al. 2018). Using this approach, the standard human-based classification of pummel images into the Pummel categories during production control is therefore automatized and objectified by using the pre-trained CNN for prediction of the Pummel class along with a statistically sound quantification of uncertainties of this process.
Since only a few labeled Pummel image data were available for training the CNN, the authors used image data augmentation to expand the training data set. First results show a prediction probability of the correct classification of the pummel value of over 80 %, cf. Fig. 13. However, a significant performance gain is expected if more actual labeled Pummel image data is available in the next step of this project. In order to show the performance of the AI Pummel tool, first validation results are illustrated in Fig. 12, where the Pummel image to classify is shown together with the CNN-based prediction of the Pummel value as well as the Pummel value determined by manufacturer (ground-truth Pummel value) is also shown.
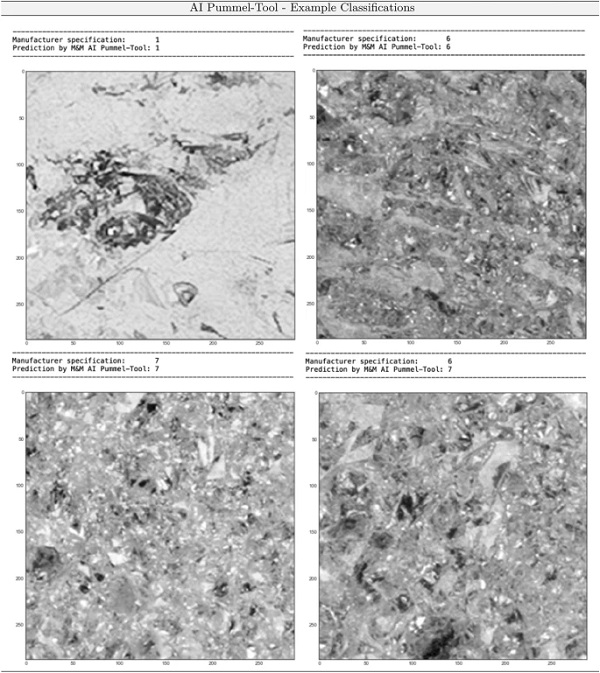
Figure 12 together with Fig. 13 proves, that the AI Pummel tool is very well able to generalize, i.e. to correctly classify Pummel images which were not used during the training of the CNN. The accuracy of the classification algorithm within the context of this paper is measured via the confusion matrix (also known as error matrix ) (cf. Fig. 13). Each row of the matrix represents the Pummel values predicted by AI, while each column represents the actual Pummel value defined by the manufacturer (ground-truth). The name confusion matrix stems from the interpretation of the algorithm, here a CNN-classifier, confusing two classes. Interpretation of the confusion matrix of the CNN is interesting, as for the pummel value classes 1, 3, 5, 7, 9 the accuracy of the prediction is over 92%.
The worst prediction result is obtained for the Pummel value class of 6, where an accuracy of 63% was found. On the other hand, the results give rise to questioning the qualitative scale of 11 classes to be lumped into e.g. 5 or 6 Pummel classes. However, since the training of the CNN was based on a small amount of publicly available data, more theoretical justification for this Pummel class lumping along with a quantification of the improvement of the performance and robustness of the CNN and further investigations on alternative architectures or even alternative approaches such as clustering (Jain et al. 1999) has to build upon future studies with an increasing amount of ground-truth Pummel images.
AI prediction of cut-edge of glass via semantic segmentation
In the production and further processing of annealed float glass, glass panes are usually brought into the required dimensions by a cutting process. In a first step, a fissure is generated on the glass surface by using a cutting wheel. In the second step, the cut is opened along the fissure by applying a defined bending stress. This cutting process is influenced by many parameters, where the glass edge strength in particular can be reproducibly increased by a proper adjustment of the process parameters of the cutting machine (Ensslen and Müller-Braun 2017).
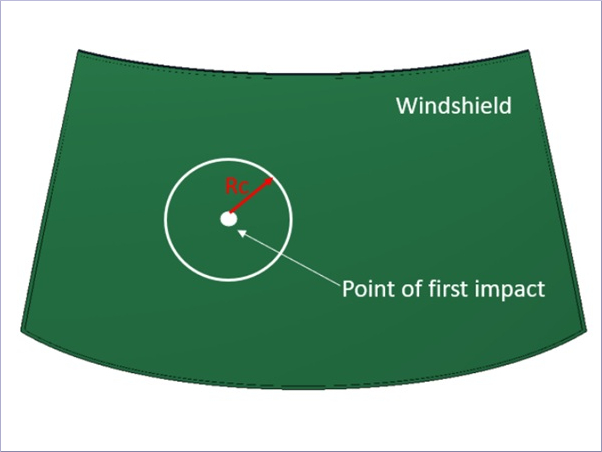
It could be observed that due to different cutting process parameters, the resulting damage to the edge (the crack system) can differ in its extent. In addition, this characteristic of the crack system can be brought into a relationship with the strength (Müller-Braun et al. 2018). In particular, it has been found that characteristics of the lateral cracks, cf. Fig. 14 viewing the edge perpendicular to the glass surface, allow best predictions for the glass edge strength (Müller-Braun et al. 2020).
The challenge here is, however, to detect these lateral cracks and the related geometry in an accurate and objective way. Currently, this is conducted by manual tracing due to the fact that the crack contour can sometimes only be recognized roughly by eye. After manually marking the crack using an image processing program, the contour is then automatically evaluated further. Methods of AI and especially the algorithms from the field of AI in computer vision now can be utilized as an alternative to the existing manual approach to automate the step of manual detection of the glass cut edge. In addition to the enormous time and hence economic savings, the objectivity and reproducibility of detection is an important aspect of improvement. The topic of image classification in the context of computer vision and DL is well known (Ferreyra-Ramirez et al. 2019). As stated in the previous section of this paper, image classification is concerned with classifying images based on its visual content.
Whilst the recognition of an object is trivial for humans, for computer vision applications robust image classification is still a challenge (Russakovsky et al. 2015). An extension of image classification is object detection (i.e. enclosing objects by a frame or box within an image). Object detection often just requires a coarse bounding of the object within an image, but in the case at hand it is desirable to extract the contours of an object as exactly as possible. Semantic segmentation in contrast to object detection describes the task of classifying each individual pixel in an image into a specific class (Guo et al. 2018). The task of semantic segmentation processes image data in such a way that an object to be found is segmented or bordered by a so-called mask.

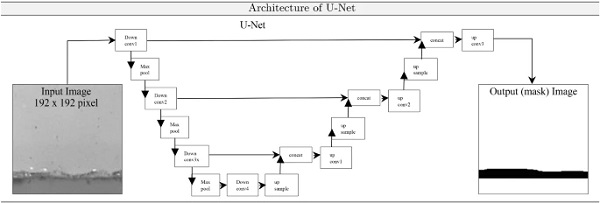
In (Drass et al. 2020) AI and especially the problem of semantic segmentation was for the first time applied to identify the cut edges of cut glass to automatically generate mask images. The goal is to process an image of a glass cut edge using the DL model U-Net (Ronneberger et al. 2015) in such a way that a mask image is generated by the model without explicitly programming it to do so.
For the problem at hand, the segmentation of the images of cut edges of glass is into two classes “breakage” (black) and undamaged glass (white), i.e. a binary segmentation, is conducted using the U-Net architecture, which is shown in Fig. 15. Accordingly, the mask image should only recognize the cut glass edge from the original image and display it in black in the mask image. More details on the the U-Net architecture, the learning algorithm and hyperparameter tuning is given in (Drass et al. 2020).
As shown in Fig 16, the trained U-Net is well suited to create a mask image from the original image without the need for further human interaction. It is also obvious that the red-yellow areas, where the NN is not sure whether it sees the cut edge or just the pure glass, are very narrow and hence of minor importance. A slight improvement of the mask images created by AI could be achieved by the cut-off condition or binary prediction. The presented NN for predicting the cut glass edge is therefore very accurate and saves a significant amount of time in the prediction and production of mask images. In addition, the mask images can be further processed, for example to make statistical analyses of the break structure of the cut glass edge. This however is not part of the present paper and will not be further elaborated hence.
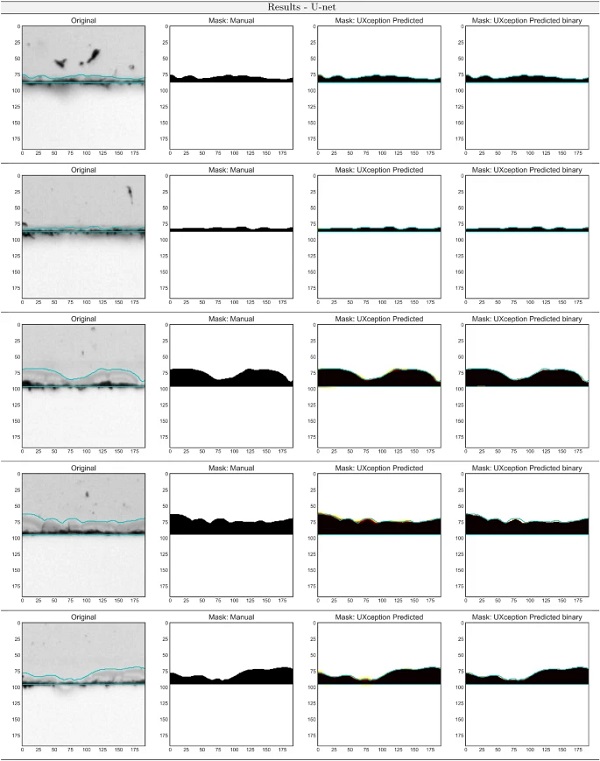
The proposed model as described briefly here and in detail in (Drass et al. 2020) showed excellent results for the prediction of the cut glass edge. The validation accuracies of both models exceeded 99 %, which is sufficient for the generation of the mask image via AI.
AI prediction of glass edge strength based on process parameters
This section deals with the prediction of the edge strength of machine-cut glass based on the process parameters of the cutting machine using supervised ML, more specifically an Extra Trees regressor, which is also known as Extremely Randomized Trees (Geurts et al. 2006).
Based on the investigations of (Müller-Braun et al. 2020), architectural glass is cut in two steps. First, a slit is created on the glass surface using a cutting tool and a cutting fluid. An integral part of the cutting tool is the cutting wheel. It is available in various dimensions, although the manufacturers make basic recommendations regarding the cutting wheel angle and cutting wheel diameter for different glass thicknesses and cutting tasks. After cutting the glass, it must still be broken by applying some bending to the pane in order to obtain two separate pieces of glass of desired dimension.
It is quite known from experience, that the edge strength of cut glass depends significantly on the applied process parameters during the cutting process, proved by simple graphical and statistical evaluation of experimental data in (Müller-Braun et al. 2020), where more details on the background of cutting and breaking glass as well as the experimental investigations of the cutting process on the edge strength of cut glass can be found. However, so far no concrete modeling approach was formulated and trained on the data given the complexity of the data correlations.
In order to deliver a prediction model of the edge strength in dependence of the process parameters of the glass cutting machine, this paper suggests a ML regression model, correlating the process parameters of cutting to the edge strength target value. With this model, it is possible for the first time to predict the edge strength in dependence of the process parameters with high statistical certainty without performing destructive tests on the cut glass. Providing this AI-based method delivers remarkable economic and ecological advantages. A lot of manpower required for testing the glass is saved along with saving resources by avoiding great amounts of glass waste material by non-destructive testing.
The main parameters of the cutting process can be summarized as follows:
- test temperature
- relative humidity
- glass thickness
- glass height
- cutting speed
- cutting force
- type of cutting fluid
- type of cutting wheel
- cutting wheel angle
- ...
Other parameters have been included in the test series, which are not described in detail here due to reasons of brevity. A total of 25 features were included for the entire test series. After applying the Boruta feature selection algorithm (Kursa et al. 2010), 12 of the 25 features could be classified as unimportant, so that the regression model was trained with a ML algorithm on a reduced number of 13 features.
The model used for this example is an Extra Trees regressor (also known as Extremely Randomized Trees) (Geurts et al. 2006), which is similar to a Random Forest regressor. SciKit-Learn (Pedregosa et al. 2011; Buitinck et al. 2013) was used together with the default hyperparameter settings for the Extra Trees regressor without further investigation on the hyperparameter tuning. The single holdout method has been applied for splitting the data in training and testing data. Figure 17 show the residuals (in MPa) between actual and predicted edge strength separately for the training and validation data.
Given the R2=0.88R2=0.88 in Fig. 17 it is concluded, that the obtained model describes the data well and the scatter is due to the dimension reduction from 25 to 13 features. On the other hand side from the validation data performance it is concluded, that alternative models calibrated with ML algorithms might be more suitable to better represent the data and the presented Extra Trees regress may lack of overfitting. A future paper will investigate in more detail an AI based model for predicting the cut glass edge strength (Fig. 18).
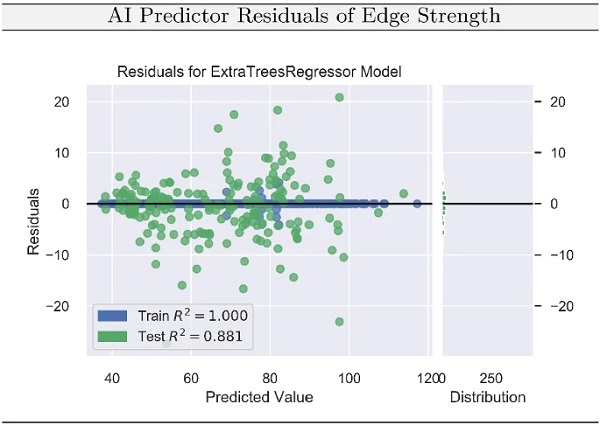
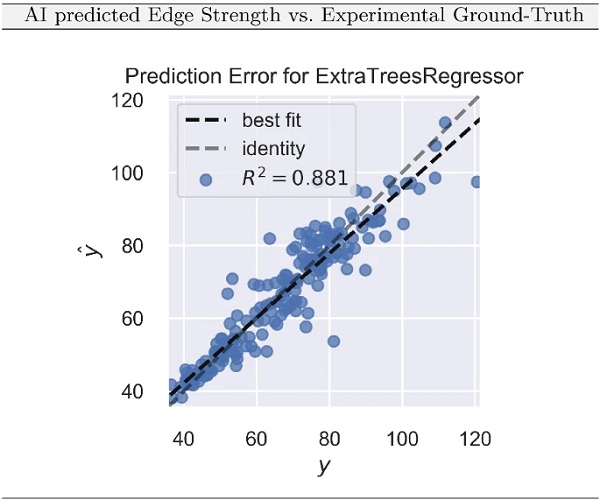
AI in structural glass engineering
This last subsection will highlight and discuss several applications of AI in the field of structural glass engineering. In the context of this paper, two examples on an already successfully conducted application of ML techniques on problems of that field and afterwards two visions for further incorporation of AI are given. Other applications of AI within structural engineering (such as design and verification of buckling for steel hollow sections or computation of deflection or bending moment fields of a Kirchhoff plate etc.) were recently published in (Kraus and Drass 2020a).
Example 1: Bayesian calibration of a Helmholtz potential for hyperelasticity of TSSA silicone
Within advanced analysis of polymeric materials in structural glass engineering constitutive models have to be applied which are able of capturing the nonlinear stress-strain relationship adequately. In (Drass 2019; Drass and Kraus 2020b), a novel functional form for the free Helmholtz energy for modeling hyperelasticity was introduced and calibrated for various polymeric materials, especially for structural silicones such as DOWSIL™ TSSA or DOWSIL™ 993 as well as glass laminate interlayers Poly-Vinyl-Butyral (PVB) and Ethylen-Vinyl-Acetate (EVA) by traditional optimization techniques. Here, a supervised ML problem for obtaining the parameters of the Helmholtz potential in a Bayesian manner is posed and calibrated.
In the context of hyperelasticity, the isochoric or volume-constant Helmholtz free energy function Ψ may be written in form of the Nelder function as
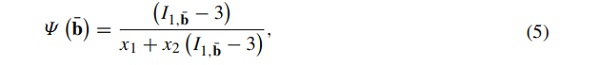
where I1,b¯=tr(b¯) characterizes the first isochoric, principal invariant of the left, isochoric Cauchy-Green tensor b¯. An extension of Eq. 5 by the second invariant of the left Cauchy-Green tensor leads to
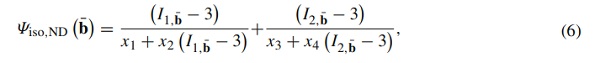
which is the final form of the novel Helmholtz free energy function.
As can be concluded from Eq.(6), the proposed Helmholtz energy possesses four parameters to be calibrated θ={x1,x2,x3,x4}.
The experimental data of the transparent silicone was presented in (Drass et al. 2018a, b), where the material was experimentally characterized in uniaxial tension and compression, shear and biaxial deformation. The second structural silicone is a carbon black filled silicone adhesive, which was investigated by (Staudt et al. 2018) for uniaxial tension and simple shear loading. The third material to be investigated is filled elastomer from the tire industry, which has been characterized under tensile and shear loads (Lahellec et al. 2004). All material parameters have been determined using Bayesian supervised ML algorithms upon the DREAM MCMC algorithm (Vrugt 2016), cf. Fig. 19. Within the context of this paper only the results for DOWSIL™ TSSA are presented for reasons of brevity.
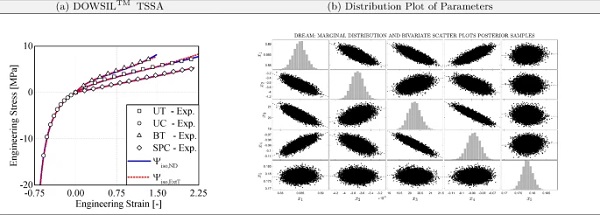
As can be seen from Fig. 19 a, the presented novel hyperelastic model Ψiso,ND and the extended tube model are well suited to represent the experimental data of TSSA for four different types of experiments. It is interesting that the MCMC simulation on a standard laptop lasted about 20 minutes and led to results (mean values of the parameters) that were very close to the smallest squares determined with the software MATHEMATICA, although MCMC means a significantly higher numerical effort compared to the smallest squares.
Finally, it is emphasized, that by applying the Bayesian framework, further deduction of partial material safety factors is straight forward as the uncertainties in the associated model parameters are naturally captured. Hence the application of Bayesian ML in this context delivers addition insight on the certainty about the model parameters as well as model assessment quantities for further use in a reliability analysis at no extra cost compared to traditional optimization-based material calibration strategies.
Example 2: Bayesian reconstruction and prediction of glass breakage patterns (BREAK)
This section deals with the application of ML to calibrate a ML surrogate of the fragmentation pattern of thermally pre-stressed glasses along with its spatial characteristics (such as e.g. fragment size, fracture intensity, etc.) via stochastic tessellations over random Strauss Point processes as initially suggested by (Kraus 2019).
Several studies on the fragmentation behavior of tempered glasses have proven relationships between the residual stress state, the glass thickness and the fragment density (Akeyoshi and Kanai 1965; Lee et al. 1965; Sedlacek 1999; Mognato et al. 2017; Pourmoghaddam and Schneider 2018). The fragment density or fracture intensity in an observation field, the fragment shape and thus the entire fracture pattern depends on the elastic strain energy density UD and thus the magnitude of the residual stress induced by a thermal pre-stressing procedure. This is shown in Fig. 20 for thermally tempered glass for different residual stress levels. It can be clearly observed that the fragment size increases with decreasing residual stress level. Approaches up to now related mean quantities such as fracture particle weight, area content or circumference (Pourmoghaddam and Schneider 2018).

To determine the characteristics of fragmentation, an ML algorithm named BREAK was developed in (Kraus 2019). The model there combines an energy criterion of linear elastic fracture mechanics (LEFM) and the spatial statistical analysis of the fracture pattern of tempered glass in order to determine characteristics of the fragmentation pattern (e.g. fragment size, fracture intensity, etc.) within an observation field. The modeling approach is based on the idea that the final fracture pattern is a Voronoi tessellation induced by a stochastic point process (a Strauss process in the context of this paper).
The parameters of that model are calibrated from statistical analysis of images of several fractured glass samples. By calibration of that stochastic point process and consecutive tessellation of the region of interest, statistically identically distributed realizations of fracture patterns can be generated. Further details on the theoretical background as well as the derivation of the model specifics for several point processes within this semi-supervised ML approach is given in (Kraus 2019). The schematic connections of the theories and experiments involved for BREAK are given in Fig. 21.
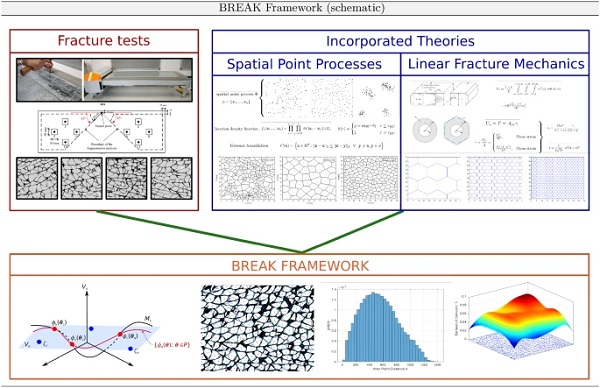
To show explicit results of the BREAK algorithm, a glass plate with thickness of t=12 mm and a defined degree of pre-stress of σm=31.54 MPa (U0=8.754 J/m3) was analysed. After the morphological processing of the fracture images, the first order statistics of the extracted point pattern were determined in the first step to infer the point process intensity. After the model parameters had been calibrated on the basis of the recorded fracture pattern photos, the simulation of statistically equivalent fracture patterns was performed using the calibrated Strauss process with induced Voronoi tessellation. An exemplary realization based on the mean values of the model parameters is shown in Fig. 22.
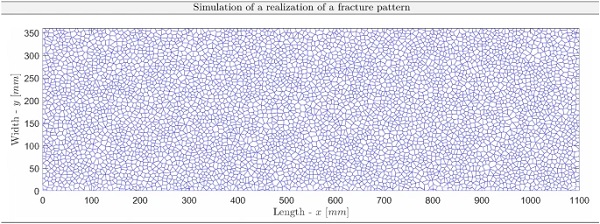
This application proved, that a combination of AI algorithms for regression and computer vision enable to model more complicated geometrical-numerical dependencies such as glass fracture patterns while carrying statistical features of its components, which was not possible by traditional approaches.
Outlook and future vision 1: AI for design and computation of structures
Within this section, a visionary outlook on the status quo and potential capabilities of AI in the fields of designing and structural verification and computation of structures is given.
Designed by AI
In this first visionary section two points will be presented and elaborated:
- design supported by AI
- structural analysis supported by AI
There are first publications dealing with the application of AI in architecture and design, cf. (Mrosla et al. 2019; Newton 2019; Baldwin 2019), in which all note that the examples of an AI-generated built environment existing today still need further years of research and cooperation between the different fields to achieve the announced quality.
For example, (Baldwin 2019) proposed a floor plan design method by Generative Adversarial Networks (GAN), cf. Fig. 23. Where a GAN is a special form of NN from the family of NN as presented in Sect. 2.3, more details on GANs may be found in (Goodfellow et al. 2016; Frochte 2019).
The GAN floor plan design pipeline uses image representations of plans as data format for both, GAN-models’ inputs and outputs, where Pix2Pix is used as GAN geared towards image-to-image translation. The careful study of the organization learned by each model revealed the existence of a deeper bias, or architectural style. The project aimed to assist the architect in generating a coherent room layout and furnishing and to finally reassemble all apartment units into a tentative floor plan The project also included the conversion of floor plans from one style to another.
A future vision of design by AI based on the works presented here is the combination of the existing GAN with customer features such as preferences for colors, shapes etc. By this, a customized design by GANs can be reached to a high consumer satisfaction level.
Structural verification supported by AI
In the context of the structural verification of certain structural members or in early design stages of a project, AI and its capabilities of establishing surrogate models can be utilized to provide fast conclusions on the structural feasibility of a designed structure without explicit computation.
Surrogate modeling without and with AI methods concern people within the computational mechanics and optimization communities since several years. An comprehensive overview is given by (Forrester et al. 2008; Adeli 2001; Wortmann et al. 2015). The need for surrogates in engineering analysis stems from employing computationally demanding methods such as the finite element models for analysis, presented in Fig. 24.
Surrogate modeling in practical terms means that the costly and time-consuming finite element model is replaced by a regression model build upon a set of simulated responses. Because observations for the training of the surrogate are obtained by the output of a simulation, the observation model does not include any observation error (except the discretization error is considered as observation noise). Within this paper, the Gaussian process regression for the construction of meta-models for the responses of a structure (cf. Fig. 24a) using covariates and a set of simulations is discussed.
In the context of surrogate modeling, the engineer has to specify the relevant responses given certain covariates (i.e. design variables), then a number of forward simulations are conducted to collect the structural responses given different combinations of design covariates. Here, some aspects have to be considered especially: (1) the definition of the prior mean functions, (2) covariance and correlation functions and (3) the formulation required for modeling cases involving heteroscedastic errors (Goulet 2020).
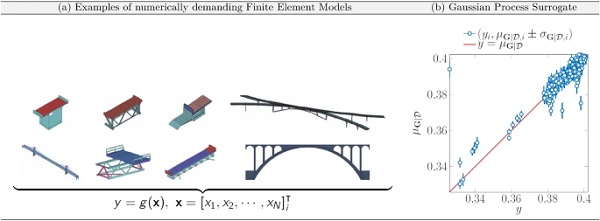
Figure 24b compares the Gaussian process regression model predictions μG with the true finite element model outputs yi. In order to obtain a meaningful comparison between predicted and measured values, it is essential to test the model iteratively using a cross-validation procedure whereas at each step, the observation corresponding to the prediction location in the validation set is removed from the training set.
A further example of providing an AI-based surrogate for fast and reliable structural design and verification of steel hollow sections was recently published by the authors in (Kraus and Drass 2020a) but it is not further elaborated at this stage. As a conclusion, using AI based surrogates for structural verification provides the computing structural engineer a fast and reliable method to check design alternatives or to conduct sensitivity analyses. Furthermore, transferability of the surrogate results is reached if a proper formulation of the engineering problem at hand is done a priori and lets further pay of a typically demanding training phase of the surrogates.
To summarize this section, AI has the potential to accelerate design and structural verification processes to a great demand while customization wishes may enter more naturally and affordably. The authors are currently at a stage, where first knowledge and experiences are gathered with these ideas. Further research of the authors will consider more building-practical applications of the presented ideas.
Outlook and future vision 2: data-driven modeling of materials within glass-structures
Especially in glass and façade construction, modern materials such as a great variety of polymers are used, but their constitutive modeling is much more complicated than established building materials due to their thermomechanical properties (Kraus 2019; Drass 2019). For more than ten years by now, a wide range of experimental and methodical work has been providing the basis for an improved understanding of the material and load-bearing behavior of these materials, whereby the latest methods place the highest demands on the engineer and the tools available such as finite element software (Drass and Kraus 2020c; Kraus and Drass 2020b; Kraus 2019; Drass 2019).
AI-supported modeling of the complex constitutive behavior of these materials is one of the latest developments in AI related computational mechanics research as the realistic simulation and design of polymeric components in civil engineering requires knowledge of the relevant mechanisms of load transfer, failure and aging (if applicable) and their effect on the load-bearing behavior. The methodical handling of the relevant processes and the transfer into modern numerical models for the reliable simulation of the constitutive behavior of synthetic polymers in civil engineering is scientifically, technically and economically highly relevant. Thus, the development and safe design of novel structures in various fields such as architecture/construction, automotive engineering and aerospace is possible.
A data-driven material modeling approach by the earlier mentioned physics-informed/theory-guided AI approach is particularly interesting as especially for engineering, in contrast to material sciences (a rather big data environment), constitutive models for design have to be created and calibrated mostly on the basis of a few experiments (usually a small data environment). The incorporation of physical laws and theoretical knowledge there is of special interest. The development of a reliable, methodologically sound and generalizable derivation of constitutive laws on the basis of techniques of AI and in particular of deep NN from experimental data thus requires a systematic analysis of the relevant mechanisms, influence parameters and modeling strategies regarding the techniques of AI, which can only succeed in a good symbiosis of the knowledge of the disciplines of material sciences, civil engineering, numerics and optimization as well as computer science.
The overall goal of a recent research project of the authors is the development of a validated and reliable methodology for the selection and calibration of suitable artificial intelligence models for modular thermodynamically consistent constitutive modeling of polymeric materials in civil engineering using experimental and simulation-based data. With such a method, complicated material models can be established on the basis of data from standard experiments and simulations to capture hyperelastic, viscoelastic and damage effects. As the framework is general, it is not only restricted to the mentioned polymer silicone and glass laminated polymers but would apply to any new material in the field.
Summary and conclusions
Within this paper the reader was introduced to the main concepts of and a brief background on Artificial Intelligence (AI) and its sub-groups Machine Learning (ML) and Deep Learning (DL). The nomenclature along with the meaning of AI core vocabulary on the task T, the performance measure P and experience E were introduced and illustrated via examples. Furthermore a detailed elaboration on the importance of splitting available data into training, validation and test set was given, which then was followed by underlining over- and underfitting of models during training by AI algorithms and strategies to avoid either of that problems.
Then two sections on the basic nomenclature and carefully chosen models from ML and DL were presented to the reader. In the main part of the paper, a review and summary of already successfully conducted applications of AI in several disciplines such as medicine, natural sciences, system identification and control, mechanical as well as civil engineering. A total of six core sections then introduced and explained in detail problems out of structural glass engineering, where AI methods enabled training a model at all or were superior compare to traditional engineering models.
The glass engineering applications range from accelerated glass product development, deep learning based quality control of glass laminates for the Pummel test, prediction of the cutting edge of glass together with prediction of the strength of the cut glass edge to the calibration of a Helmholtz potential and the prediction of the fracture pattern of thermally pre-stressed glass. For all examples the amount of necessary data together with the challenges and final solution strategy was reported to enable the reader to judge temporal and monetary effort for AI methods in comparison to existing engineering models and approaches (in case these are existing).
Here several points for taking care or differences in an (structural façade and glass) engineering context to traditional computer science approaches to AI where highlighted. It was stated that especially the availability of data in an engineering context is limited due to monetary or confidentiality reasons and thus the establishing of publicly accessible databases is hardly possible for a greater audience, however on the level of individual companies or research groups, the data stock problem is not severe or even present. Finally a visionary outlook on the role of AI within supporting engineers for an early stage design of structures, the modeling of advanced material behavior by physics-informed AI approaches as well as AI-based structural verification surrogates finished the paper.
Within this paper the following conclusions are reached:
- AI-supported control of adaptive façades will potentially solve the multi-criteria optimization problem involving economy, sustainability and user-well being
- several examples of a successful application of AI in the field of structural glass engineering were provided and proofed superior compared to existing approaches
- for the first time ever, AI models made it possible to establish numerical predictions for phenomena such as glass fracture patterns or cut edge strength
- the amount of available data for training AI models is often limited and hence constrict attainable model accuracies and generalizations, e.g. for the Pummel test as well as the cut edge strength examples
- AI-based models can easily be enhanced by uncertainty quantification methods to establish reliability statements, e.g. in the case of polymeric materials for structural glass engineering or the accuracy of predicting the Pummel value
- future research and industry potentials ly in the elaboration of AI-empowered design and verification support systems, which enable to consider user/occupant demands as well as structural reliability and serviceability already in early planning stages
In principle, we consider the introduction of AI technologies in glass and façade construction and its neighboring industries to be possible to a great extend already immediately, since the essential basis of an AI, i.e. the existence of data, is already fulfilled in many cases. A first task for research and especially industry will now be to structure the existing data in such a way that AI algorithms can apply, train and validate diverse models on it in order to lead to successful projects in combination with engineering expertise.
The theoretical framework and the respective software are in place but have to be augmented by the knowledge of structural/civil engineers, who are familiar with the statistical and methodical concepts of AI. For this reason, in the eyes of the authors of this paper, it is essential to introduce these methodological knowledge and practicing with AI in the study curricula of students of civil engineering and architecture in the near future as well.
Acknowledgements
We would like to express our greatest gratitude to our numerous industry and research partners for fruitful discussions on the topic and providing samples of material or data. Especially the support by Stanford University (Prof. Christian Linder, PhD @ CEE) as well as TU Darmstadt (Prof. Dr.-Ing. Jens Schneider @ Fachgebiet Statik) along with their great academic guidance and support is highly appreciated. May this article and our research further impact the civil and structural glass engineering community.
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Affiliations
M&M Network-Ing UG (haftungsbeschränkt), Lennebergstr. 40, 55124, Mainz, Germany
M. A. Kraus & M. Drass
Civil and Environmental Engineering, Stanford University, Y2E2, 473 Via Ortega, Stanford, CA, 94305, USA
M. A. Kraus
Institute of Structural Mechancis and Design, Technische Universität Darmstadt, Franziska-Braun-Str. 3, 64287, Darmstadt, Germany
M. A. Kraus & M. Drass